8 Data import
8.2 入门
readr有很多函数提供类似的使用方法实现对不同格式平面文件的读入,下面以read_csv函数为例学习这些函数一般的用法。
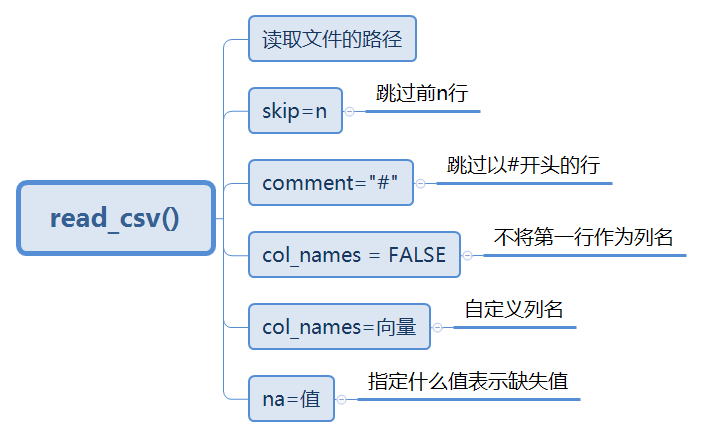
read_csv常用参数:
8.3 解析向量
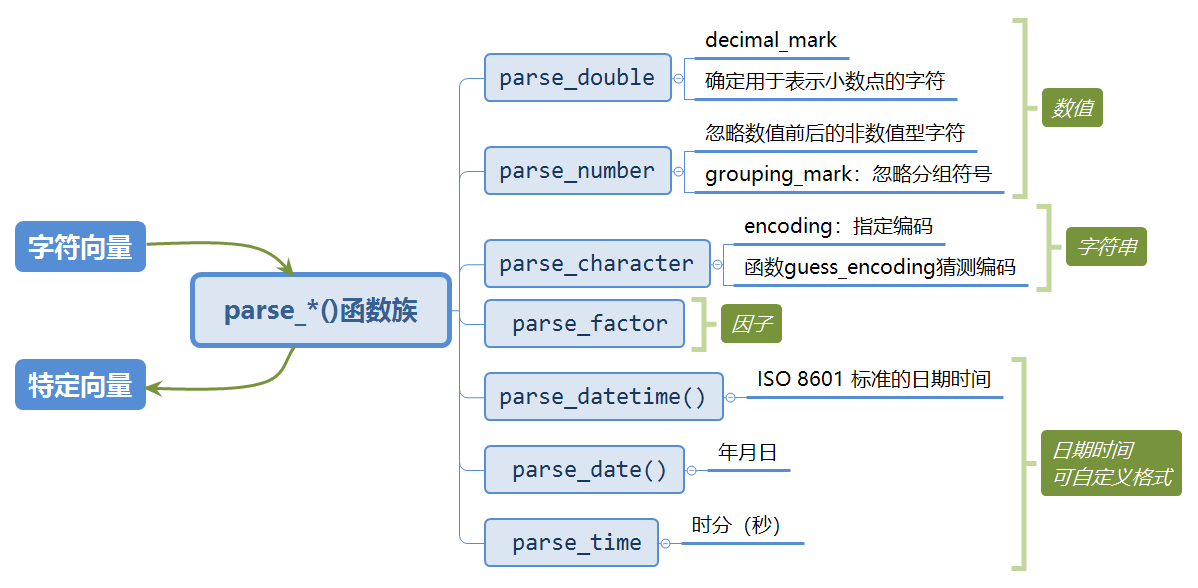
我们先学习parse_*()函数族,它们接收一个字符串,然后返回一个特定数据类型的向量。
各函数的用法大致一样,第一个参数是需要解析的字符向量,na参数设定了哪些字符串应该当作缺失值来处理。解析失败的值在输出中是以缺失值的形式存在的。
各函数的作用大致如下:
8.4 解析文件
8.4.1 策略
readr使用一种启发式过程来确定每列的类型:先读取文件的前1000行,使用guess_parser()函数返回readr最可信的猜测,接着parse_guess()函数使用这个猜测来解析列。
8.4.2 问题
按照上面的策略来进行当然不可能万无一失。可能遇到的问题:
前 1000 行可能是一种特殊情况,
readr猜测出的类型不足以代表整个文件。列中可能含有大量缺失值。
每个
parse_xyz()函数都有一个对应的col_xyz()函数。如果数据已经保存在R的字符向量中那么你可以使用parse_xyz();如果想要告诉readr如何加载数据,则应该使用col_xyz()。 我们强烈建议你总是提供col_types参数,从readr打印出的输出中可以知道它的值。这可以确保数据导入脚本的一致性,并可以重复使用。如果不提供这个参数,而是依赖猜测的类型,那么当数据发生变化时,readr会继续读入数据。如果想要严格解析,可以使用stop_for_problems()函数:当出现任何解析问题时,它会抛出一个错误,并终止脚本。
8.4.3 其他策略
对于上面的问题,我们需要其他的策略:
设置
guess_max读多几行数据将所有列都作为字符向量读入,再结合
type_convert()函数如果正在读取一个非常大的文件,那么你应该将
n_max设置为一个较小的数,比如10 000或者100 000。这可以让你在解决常见问题时加快重复试验的过程。如果遇到严重的解析问题,有时使用
read_lines()函数按行读入字符向量会更容易,甚至可以使用read_file()函数读入一个长度为1的字符向量。接着你可以使用后面将学到的字符串解析技能来解析各种各样的数据形式。
后两个策略暂时不太明白…
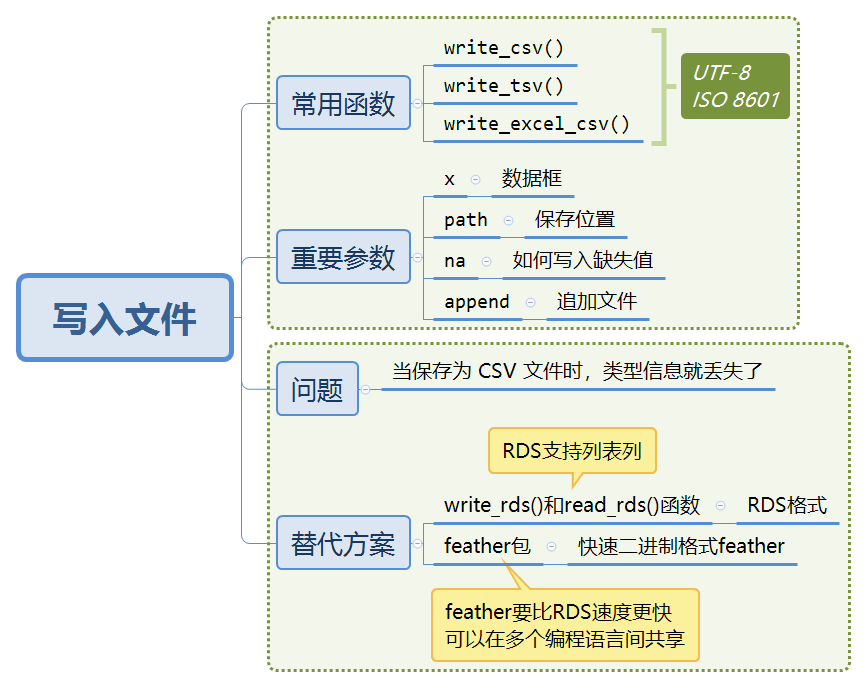
8.5 写入文件
8.6 练习
(1)有时CSV文件中的字符串会包含逗号。为了防止引发问题,需要用引号(如 " 或 ’)将逗号围起来。按照惯例,read_csv()默认引号为",如果想要改变默认值,就要转而使用read_delim()函数。要想将以下文本读入一个数据框,需要设定哪些参数?
通过设置quote参数指定引号。
(2)找出以下每个行内 CSV 文件中的错误。如果运行代码,会发生什么情况?
read_csv("a,b\n1,2,3\n4,5,6")
#> Warning: 2 parsing failures.
#> row col expected actual file
#> 1 -- 2 columns 3 columns literal data
#> 2 -- 2 columns 3 columns literal data
#> # A tibble: 2 x 2
#> a b
#> <dbl> <dbl>
#> 1 1 2
#> 2 4 5
read_csv("a,b,c\n1,2\n1,2,3,4")
#> Warning: 2 parsing failures.
#> row col expected actual file
#> 1 -- 3 columns 2 columns literal data
#> 2 -- 3 columns 4 columns literal data
#> # A tibble: 2 x 3
#> a b c
#> <dbl> <dbl> <dbl>
#> 1 1 2 NA
#> 2 1 2 3列数不匹配,不是矩形数据。read_csv以第一列列数识别为文件列数,后面的数据列数不够部为NA,超过的截断。
x <- "a,b\n\"1"
cat(x)
#> a,b
#> "1
read_csv(x)
#> Warning: 2 parsing failures.
#> row col expected actual file
#> 1 a closing quote at end of file literal data
#> 1 -- 2 columns 1 columns literal data
#> # A tibble: 1 x 2
#> a b
#> <dbl> <chr>
#> 1 1 <NA>估计是把"1识别为整数1。
将a;b与1;3识别为字符串了。